机器学习中的正则化方法
本文共 494 字,大约阅读时间需要 1 分钟。
参数范数惩罚
L1 L2 regularization
正则化一般具有如下形式:(结构风险最小化)
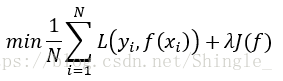
其中,第一项是经验风险,第二项是正则化项,lambda>=0为调整两者之间关系的系数。
正则化项可以取不同的形式,如参数向量w的L2范数:
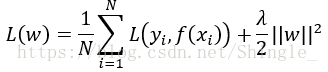
假设以平方差为损失函数,则优化目标为:
minw∑i=1m(yi−wTxi)2+λ||w||22 m i n w ∑ i = 1 m ( y i − w T x i ) 2 + λ | | w | | 2 2
正则化项也可以是参数向量w的L1范数:
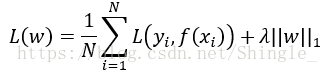
minw∑i=1m(yi−wTxi)2+λ||w||1 m i n w ∑ i = 1 m ( y i − w T x i ) 2 + λ | | w | | 1
L1范数和L2范数都有助于降低过拟合风险,但前者还会代来一个额外的好处:它比厚泽更易获得“稀疏”(sparse)解,即它求得的w会有更少的非零向量。

数据集增强
噪声鲁棒性
Dropout
神经网络
early stopping
提升方法
神经网络
Bagging和其他集成方法
《统计学习方法》 1.5.1 P14
《深度学习》 7
你可能感兴趣的文章
jvm_tool jconsole/ jprofiler/ JProbe/ VirtualVm/ TPV/ YourKit/ ITCAM/ MAT/ MDD4J
查看>>
IBM WebSphere Performance Tool / ISA / jca457.jar / ha456.jar / ga439.jar
查看>>
IBM WebSphere Commerce Front_dev
查看>>
IBM WebSphere Commerce Developer Business Edition
查看>>
IBM Tivolli Composite Application Manager / IBM ITCAM
查看>>
IBM WebSphere Commerce Analyzer
查看>>
Unix + OS IBM Aix System Director
查看>>
Unix + OS IBM Aix FTP / wu-ftp / proftp
查看>>
framework apache commons
查看>>
my read work
查看>>
blancerServer IBM WebSphere Edge Server 6.1
查看>>
db db2 base / instance database tablespace container
查看>>
my read _job
查看>>
hd disk / disk raid / disk io / iops / iostat / iowait / iotop / iometer
查看>>
project ASP.NET
查看>>
Linux + OS SUSE 11 / OpenSUSE 11
查看>>
net monitor nagios / cacti / solarwinds / tivoli netcool / Vyatta
查看>>
monitorServer IBM Tivoli Enterprise Monitor Server
查看>>
hd Aruba wifi / honor
查看>>
db db2 v9.7 / 9.8
查看>>